We know that you’ve probably heard of object oriented programming (OOP), but outside of designing games, when is best to use it for data science? We haven’t used OOP much until recently when we refactored a data science project code base. In this article, we give a brief refresher for OOP and discuss our top reasons for using OOP with a few examples.
When we code, we generally skew towards more of a functional style of programming, but sometimes we get frustrated with code that is too long. This means that we focus on building our code using functional modules of code and functions. However, at some point, our functions become too large to keep track of and we consider refactoring into classes.
Classes vs Functions
I like using functions for their modularity capability. If I have more than 3 functions related to a specific capability, then I move all functions into a custom module and import this module into my driver script. If I can apply these functions to one specific object type, then I will consider refactoring the module into a class. If these underlying functions can be used more widely within the code base, then I would tend not to use classes because that would mean duplicating code.

When I have more than 3 functions, I will consider creating a class instead of the custom module if the new operation is done by the object, instead of on the object. Creating classes enables the containment of data and adds structure to the code that helps make it more extensible and reusable.
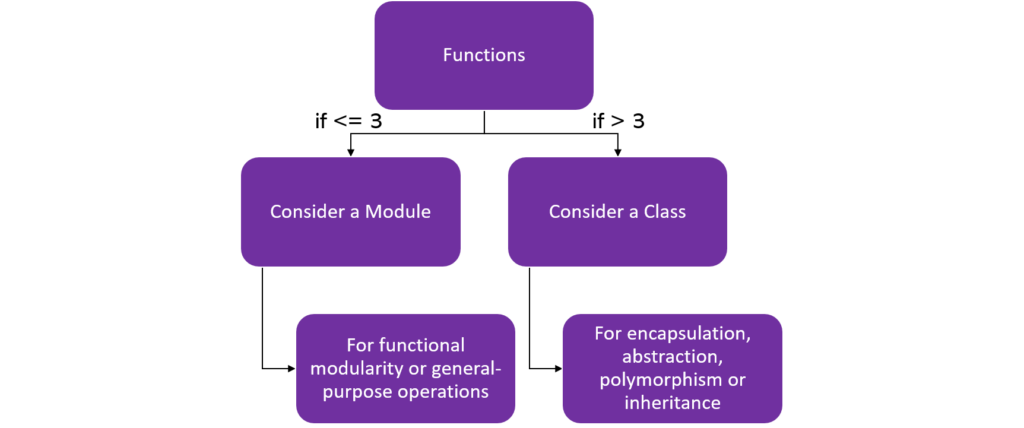
Use a class when you need to:
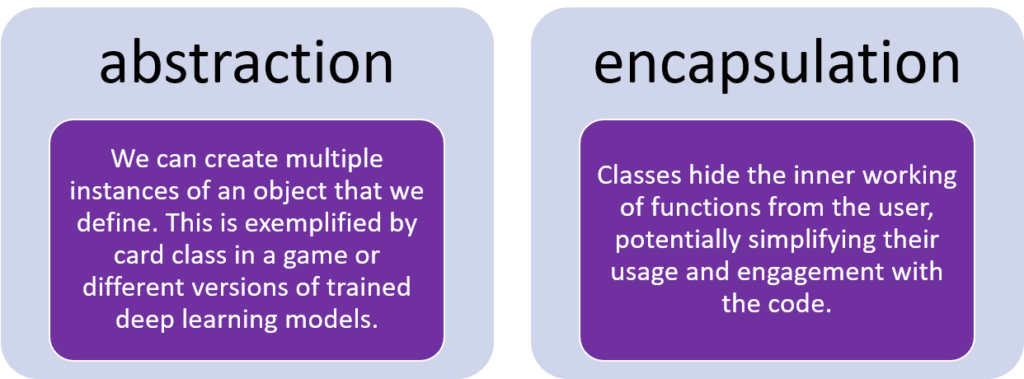
- Isolate calling code from implementation details – taking advantage of abstraction and encapsulation. This principle lets the developer hide irrelevant implementation and class details from the user. With instances of classes, the user only sees the basic operations on a class instance. If an operation is not instance specific, then it should not be a member function.
- Reuse objects to take advantage of inheritance and/or polymorphism. You can leverage the framework that we already have in place by extending functionality of a parent class. Using inheritance and polymorphism capitalizes on the flexibility of our code, ultimately saving the developer time on remembering how the code works and extending the code to add more functionality.

It is helpful to think of an object as a dog. Attributes are the dog’s characteristics such as name, height, and breed. Methods and functions are operations that the dog can perform. If an operation could be performed without requiring an attribute that is unique to this dog (and without changing anything on this dog object), then the operation should be written as a function. Otherwise, the operation should be written as a method of the class such as fetch, sit or roll over. This analogy is a bit of a simplification but is a good start to deciding whether you need a function vs. method.
Examples of Classes for Data Science
- Constructing a data processing pipeline. For example, when preparing text for NLP analytics, we may have a processed text class object with methods for lemmatizing, removing stop words, chunking sentences and performing topic modeling.
- Training and Testing ML models. We could design a ML model class that enables training and testing on different sets of data as well as instantiates slightly different versions of a model with the same underlying architecture.
- Plotting. We can add plotting utility functions specific to a ML model like diagnostics plots such as plotting fitted values vs residuals.
Pro-tips for building classes
- Dunder methods can be useful for object representation, iterating over, merging and comparing objects. __init__ is a must, but there are several others that enhance the user experience and simplify your coding life like: __call___, __add__, __lt__, __getitem__ and __len__. This website does an awesome job at explaining why and how to use dunder methods, so check it out!
- Class variables vs Instance variables. Class variables are available to all class objects, while instance variables are specific to a class instance.
- Consider using namedtuples instead of classes for record tracking-type applications. namedtuples are implemented as Python classes internally, saving you some work. Namedtuples are immutable so you cannot change attribute values once set. These are more readable and easy to create as well as work with. They are memory efficient, just like tuples. For more on namedtuples (like how to extend them), read this.
from collections import namedtuple
Car = namedtuple('Car' , 'color mileage')I tend to prefer a functional programming style when I start a new project and/or I need to hash out some code quickly. However, I like switching to the OOP style when the code base grows beyond 3 distinct “capabilities”. When and if you decide to do OOP, you gain in readability and hierarchical organization of your code that makes it easy for others to understand.