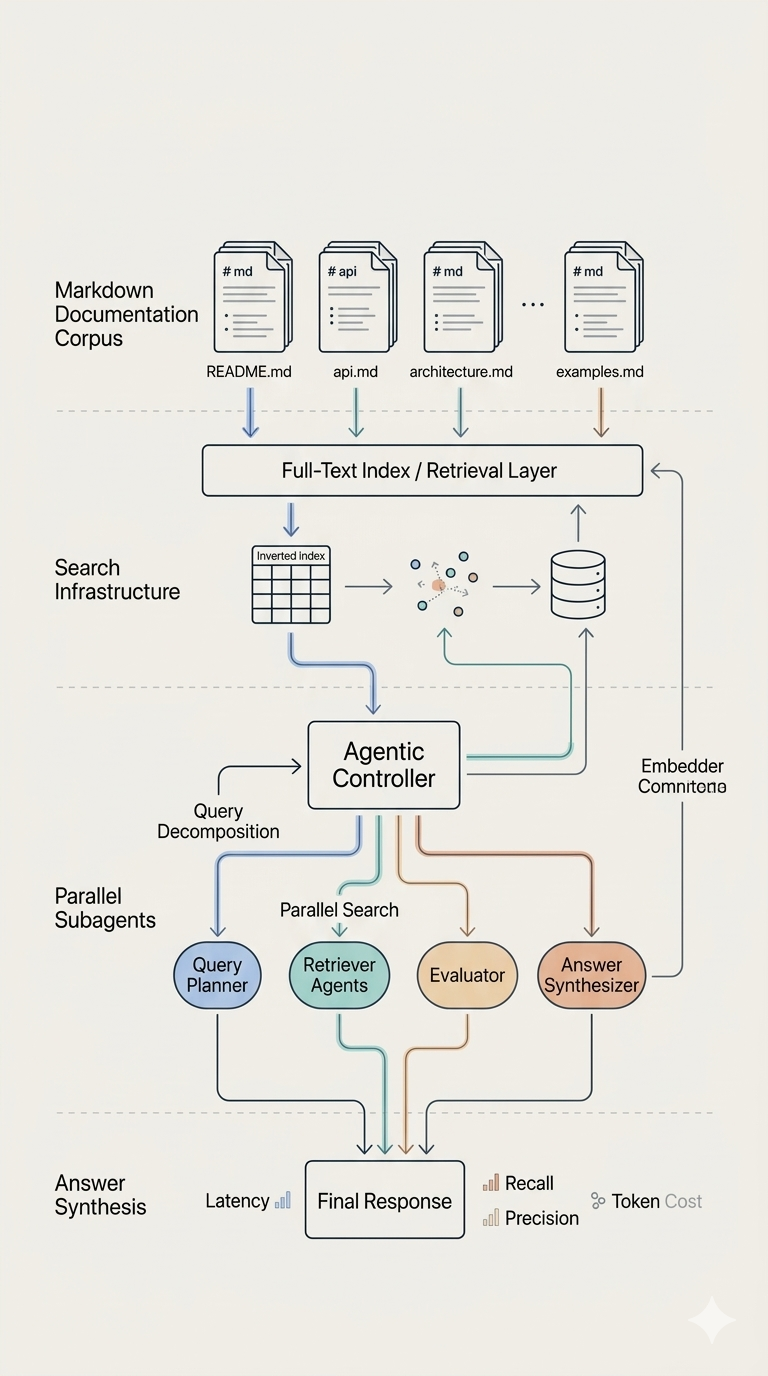
While traditional RAG relies on static vector lookups that often lose global context, agentic search transforms retrieval into a dynamic, reasoning-driven process. By utilizing hierarchical structures like RAPTOR, Knowledge Graph RAG and autonomous sub-agents, these systems can navigate complex, multi-hop queries that typically overwhelm standard semantic search. This shift from one-shot retrieval to iterative loops allows for parallelized processing and self-correction, ultimately providing the precision and structural awareness required for professional-grade document analysis.
I spent a week implementing agentic search over code documentation using four different approaches — from filesystem-based agents to token-optimized parallel subagent architectures. I wanted to understand when agents add value to RAG systems, and when they just add complexity.
The short answer? If your application has low latency, low token cost and simplistic user query constraints, you probably don’t want agentic search. But when you do, the implementation details matter far more than I expected.
Here’s what I learned.
Lesson 1: Agents Don’t Replace Indexes — They Orchestrate Them
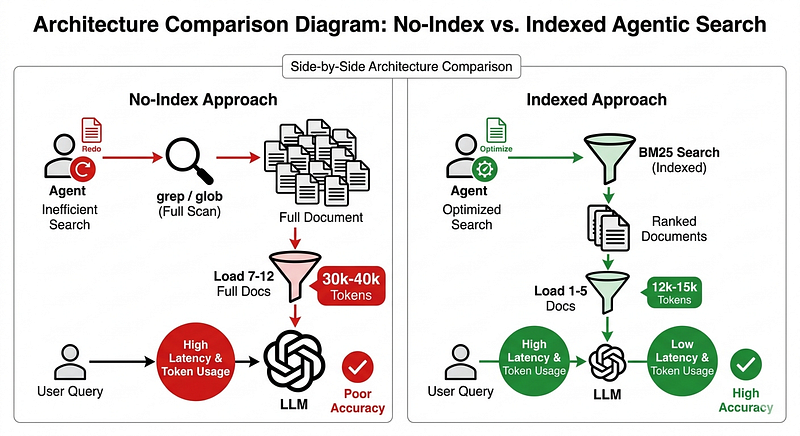
The misconception: Agents can just grep through your documentation and figure it out.
The reality: This works for tiny corpora (10–20 files), but it’s wildly inefficient without significant corpus organization.
I built two approaches without any indexing:
- Approach 1: DeepAgent with filesystem tools (
grep,glob,read_file) - Approach 2: DeepAgents CLI (same filesystem access, different interface)
Both worked perfectly on my 12-file test corpus. 100% hit rate, good answers with citations. But here’s the problem: they loaded 7–12 full documents per query into context. No ranking, no filtering — just brute-force retrieval.
Token usage: ~30k-40k input tokens per query
Latency: 32–34 seconds average
Scalability: Likely breaks down at ~50+ files
Compare that to the full-text (not semantic) indexed approaches (BM25 via Tantivy):
- Token usage: ~12k-15k input tokens per query
- Latency: 35–79 seconds (depends on architecture)
- Scalability: Handles 1000+ files easily
The lesson: Agents are great at orchestrating retrieval (deciding what to search for, when to read full content, how to combine results). They need tools that leverage a real search engine or grep’ing 10k characters at a time.
Lesson 2: No-Index Approaches Work (But You Probably Shouldn’t)
Here’s what surprised me: the filesystem-based agents actually worked well for my use case.
Why? Three reasons:
- Small corpus (12 well-organized markdown files)
- Pre-chunked documents (each file covers one topic)
- Claude Sonnet 4.5 has a huge context window (200k tokens)
If your documentation fits these criteria, skipping the index is tempting. No Tantivy setup, no vector database, no embedding pipeline. Just point the agent at a folder and go.
When this makes sense:
- Prototyping (get results in hours, not days)
- Internal tools with <20 frequently-changing docs
- Documents already well-structured by topic
When it breaks down:
- Corpus grows past 50 files (context poisoning)
- Documents are long-form, multimodal content (books, transcripts, reports)
- You need to scale to multiple users (token costs explode)
I kept the filesystem approach in my repo as “Approach 1” specifically for quick prototyping. It’s the fastest way to test if agentic search is even right for your problem. I tested out the DeepAgent CLI, but you could use any coding agent (OpenCode, pi, Claude Code, Codex, etc.) to achieve the same effect and evaluate other agent harnesses.
Lesson 3: Parallel Search via Sub-Agents Was Slower
This was the biggest surprise.
I built Approach 4 to spawn 2 subagents in parallel, each formulating different query variations to search the corpus. The idea: cast a wider net, find more relevant documents, improve recall.
Expected: ~30–40 seconds (similar to baseline)
Actual: 79 seconds on average — more than 2× slower
Why? Orchestration overhead dominates everything.
Here’s what happens in the parallel subagent architecture:
- Parent agent reads the query
- Parent agent formulates 2 query variations
- Parent agent dispatches both via
tasktool - Two subagents run in parallel (good!)
- Parent agent waits for both to finish
- Parent agent consolidates results
That’s a minimum of 3 serial LLM round-trips (plan → execute → consolidate), even though the subagents themselves run in parallel.
Compare to the baseline (Approach 3 — direct tool access):
- Agent searches Tantivy index with BM25
- Agent reads relevant documents
- Agent generates answer
Just 1–2 round-trips. Way faster.
The tradeoff: Parallel subagents did consult more diverse files (2–4 vs 1–2), but the recall improvement was marginal. For most queries, it wasn’t worth the latency hit.
When parallel subagents make sense:
- Multi-hop reasoning queries (“How do I build X that uses Y and Z?”)
- You genuinely need exhaustive search
- Latency is secondary to recall
Otherwise? Stick with direct tool access.
Running an agent to reason over every search query can be costly and slow. We can address this by using Haiku or a smaller LLM as the sub-agent or using Recursive Language Models (RLM), which may achieve the effect of parallel sub-agents without the latency hit or context rot. Another approach is use a high-reasoning coding agent once to generate optimized Python code that can replace an LLM call. For example, you curate a high quality “training set” of queries and results, then you ask the coding agent to find the patterns of what makes a result “good” and write a Python function (def rerank(...)) that implements those patterns using logic (e.g., “If the brand name is in the first 3 words of the title, boost the score”). Calling a python function is reliable, low latency (milliseconds vs seconds) and scales high-quality search to millions of users, as compared to executing a live agentic reranker.
Lesson 4: Middleware Bloat Will Eat Your Token Budget
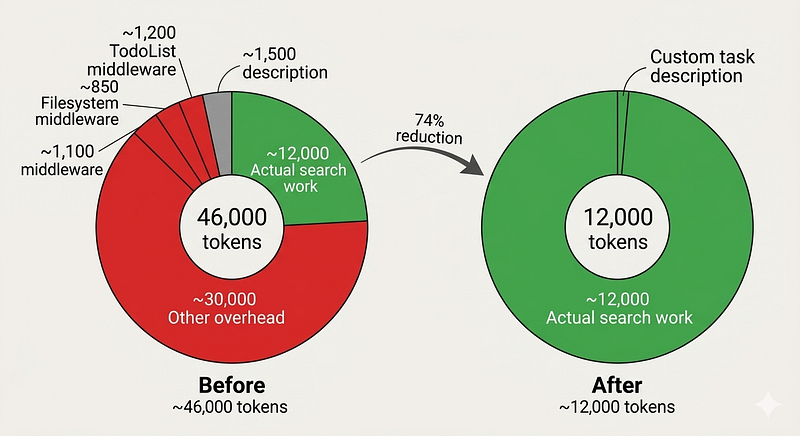
Here’s the token optimization story that saved my implementation.
My initial parallel subagent architecture hit Anthropic rate limits (30k input tokens/min). Per-query consumption: ~46,000 tokens. I couldn’t run more than one query without errors.
The culprit? Default middleware from create_deep_agent:
TodoListMiddleware (~1,200 tokens/call)
FilesystemMiddleware (~850 tokens/call)
MemoryMiddleware (~1,100 tokens/call)
SubAgentMiddleware with 6,914-char default description (~1,500 tokens)
For a search-only workflow, I didn’t need todos, filesystem access, or memory loading. That’s ~4,650 tokens of pure overhead per query.
The fix: Switch from create_deep_agent to create_agent (bare LangChain) and manually construct a minimal middleware stack:
agent = create_agent(
model=llm,
tools=[search_docs, read_docs],
default_middleware=[
SubAgentMiddleware(
task_description=CUSTOM_TASK_DESCRIPTION, # 400 chars vs 6,914
default_middleware=[], # Strip subagent middleware
),
SummarizationMiddleware(),
AnthropicPromptCachingMiddleware(),
PatchToolCallsMiddleware(),
],
)
Result: 46,000 → 12,000 tokens per query (74% reduction)
The lesson: If you’re using DeepAgents (or any framework with middleware), audit your token usage. Most frameworks enable features you don’t need. Strip them out.
How to diagnose:
- Enable LLM Observability (e.g. LangSmith) tracing
- Look at input token count per LLM call
- Check system prompts for tool descriptions you didn’t add (assuming the prompts are open-source)
Lesson 5: Simple Beats Clever (Most of the Time)

After building all four approaches, here’s what actually performed best:
Approach 3 (LangGraph + Tantivy full-text index, no subagents):
- Latency: 34.6s average
- Hit rate: 100%
- Files consulted: 1–5 per query
- Token efficiency: Good (two-phase search)
It’s the boring, straightforward implementation:
- BM25 search returns ranked previews
- Agent decides which documents to read
- Agent generates answer with citations
No parallel subagents. No clever query reformulation. Just good retrieval + agent reasoning.
The fancier approaches (parallel subagents, filesystem-based) had their moments:
- Filesystem was faster to prototype (no index setup)
- Parallel subagents retrieved more diverse files
But for production use? The baseline won on latency, simplicity, and consistency.
When to go fancy:
- You’ve already built the baseline and it’s not good enough
- You have specific evidence that parallel search improves recall
- You’re willing to accept 2× latency for marginal accuracy gains
Start here instead:
- BM25 or hybrid search (BM25 + embeddings)
- Two-phase retrieval (preview → read)
- Agent with direct tool access (no subagents)
Optimize the fundamentals first. Add complexity only when you have metrics proving you need it. Instead of a complex backend, developers should let the agent build a “mental model” of the tool. The agent can then use its reasoning to iteratively adjust queries and evaluate results (LLM-as-a-judge).
What’s Next?
These experiments were scaffolding — small corpus (12 files), limited test set (5 questions). The real work is:
- Hybrid retrieval: Combine BM25 with semantic search (embeddings) for better coverage
- Chunk-level retrieval: Return relevant chunks, not full documents (faster, less context bloat)
- Larger evaluation: 50+ questions with multi-hop reasoning and adversarial queries
- Context compaction: Apply models like Provence or LLMLingua-2 to compress prompts with retrieved content
The goal isn’t to prove agentic search is better than traditional RAG (with semantic search). It’s to understand when agents add value — and when they just add cost.
Another factor to consider is the use of long-term memory for agent self-improvement. By saving past interactions and reasoning, the agent can create a knowledge graph of what queries worked. Semantic caching allows the agent to recall successful strategies for similar future queries.
Summary & Recommendation
If you’re building RAG today:
Start with semantic search or BM25 + direct LLM access (no agents). Get your retrieval working first.
Add agents when you need:
- Multi-step reasoning over search results
- Dynamic tool selection (search vs. read vs. filter)
- Conversational memory across queries
Don’t add agents for:
- Basic document Q&A (embeddings + reranking work fine)
- Single-hop retrieval (“What does X mean?”)
- Cost-sensitive applications (agents add 2–3× token overhead)
And if you do build agentic search? Predictability > Sophistication: Agents perform better when given a “dumb” keyword search (BM25) with a clear, predictable relationship between input and output. Measure everything. Token usage, latency, hit rate, response quality. The difference between a clever architecture and an over-engineered mess is whether you can prove it’s worth the complexity.
You can check out the repository and full technical writeup.
References
- https://blog.langchain.com/deep-agents/
- https://machinelearningmastery.com/beyond-vector-search-5-next-gen-rag-retrieval-strategies/
- https://datathrillz.com/the-evolution-of-agentic-search/
- https://softwaredoug.com/blog/2025/09/22/reasoning-agents-need-bad-search
- https://softwaredoug.com/blog/2026/01/08/semantic-search-without-embeddings
- https://softwaredoug.com/blog/2025/10/19/agentic-code-generation-to-optimize-a-search-reranker