
Code Indexing and Search: The Foundation of Agent Intelligence
Before diving into what makes Claude Code exceptional, it’s essential to understand how coding agents find and navigate information in codebases. This capability fundamentally determines an agent’s effectiveness, as no amount of reasoning power matters if the agent cannot locate relevant code.
Approaches to Code Search
Modern coding agents employ three primary strategies for code discovery, each with distinct tradeoffs:
Syntactic indexing: Parsing code to understand file structures, classes, functions, and variables, enabling searches by code constructs rather than just strings.
Semantic Search via RAG (Retrieval-Augmented Generation) represents the embedding-based approach. Tools like Cursor and Windsurf create vector embeddings of code chunks, storing them in vector databases for semantic similarity search. When a developer asks “where do we handle user authentication?”, the system converts this query into an embedding and retrieves semantically similar code segments. This approach excels at refactoring or feature discovery by understanding intent and finding conceptually related code even when exact keywords differ. However, RAG systems require significant upfront indexing, consume substantial memory, and can struggle with very large codebases exceeding their embedding coverage.

Pattern-based search with ripgrep takes a fundamentally different approach. Instead of semantic understanding, tools like ripgrep perform blazingly fast regex pattern matching across entire codebases. When searching for function.*authenticate, ripgrep can scan millions of lines in milliseconds. This deterministic approach guarantees you’ll find exact matches and works consistently regardless of codebase size. The limitation lies in requiring developers or agents to know what patterns to search for—you cannot ask ripgrep to “find authentication logic” without translating that intent into concrete patterns.
Sub-agent search delegation represents Claude Code’s innovative approach. Rather than relying solely on pre-indexed embeddings or pattern matching, Claude Code can spawn specialized sub-agents tasked with search missions. These sub-agents receive focused prompts like “find all template rendering code” and autonomously execute multiple search strategies in their own context windows. They might start with broad Glob patterns to identify relevant directories, then use Grep for specific patterns, then read promising files to verify relevance. This dynamic, multi-strategy approach combines the flexibility of semantic understanding with the precision of pattern matching.
More importantly, sub-agents prevent search activities from polluting the main agent’s context window. When a sub-agent investigates twenty candidate files to find the right authentication middleware, those file contents never burden the supervisor agent’s 200,000 token context limit. The sub-agent returns only a concise summary of findings, preserving the supervisor’s ability to maintain strategic oversight of the larger task.
Other features that make Claude Code special include the streaming JSON parser with recovery and smart data truncation when sending data to LLMs or telemetry services. The JSON parser enables elegant handling of common LLM streaming issues such as fragmented JSON output from the LLM while traditional JSON parsers fail on incomplete input.
The Four Pillars of Claude Code’s Architecture
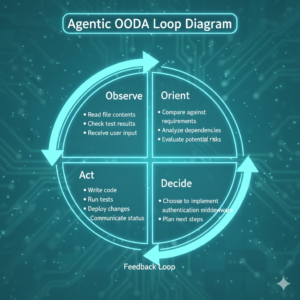
1. Planning with the Todo Tools
Effective agents must be able to articulate their plan before diving into execution. Claude Code implements this through its TodoWrite and TodoRead tools, which create structured task lists visible to both the agent and the developer. This serves multiple critical functions beyond simple organization. Note that current Claude Code versions may no longer have an explicit TodoRead tool but the functionality is rolled into TodoWrite tool.
First, the todo list forces the agent to decompose ambiguous requests into concrete, actionable steps. When asked to “add user authentication,” Claude Code creates todo items like “Create User model with password hashing,” “Implement JWT token generation,” “Add authentication middleware,” and “Write authentication tests.” This decomposition process catches many planning errors early—if the agent cannot articulate specific steps, it likely doesn’t understand the task.
Second, todo items have explicit states: pending, in_progress, and completed. This state tracking keeps the agent grounded in what it has actually accomplished versus what remains. Without this mechanism, agents frequently lose track of progress in long-running sessions, sometimes re-implementing features or skipping critical steps.
Third, the todo system provides transparency to developers. You can see at a glance what Claude Code plans to do next, allowing you to course-correct before the agent heads down an incorrect path. This human-in-the-loop oversight proves essential for complex tasks where requirements may be ambiguous or partially specified.

The todo system also helps agents recover from context truncation. In extremely long sessions exceeding the 200,000 token context limit, early conversation turns get truncated. The todo list persists as a compressed representation of the overall plan, allowing the agent to maintain strategic coherence even as tactical details from earlier in the session fade from active context. This task list provides transparency into Claude’s plan for the user, keeps the agent focused, and supports complex, multi-step workflows with real-time progress visibility.
2. Memory Through Filesystem Persistence
Claude Code treats the filesystem itself as its primary memory system. It reads and writes files actively as it executes tasks, allowing it to store intermediate results and learnings persistently. This design decision, while seemingly simple, enables maintenance of long-running context by extracting and compressing insights from executed code.
The key innovation lies in special files like Agents.md or Claude.md that serve as compressed knowledge bases about a codebase. When Claude Code encounters recurring patterns, makes mistakes, or learns important architectural principles about your project, it can append guidance to these files. Over time, these documents become condensed playbooks capturing institutional knowledge.

For example, after struggling with a particular dependency’s API, Claude Code might add a note: “The DataProcessor class requires explicit cleanup via close() after use. Always wrap in try-finally blocks. See src/utils/processor.py for examples.” Future sessions can read this guidance before working with that dependency, avoiding the same pitfall.
Filesystem-based memory remains local to each project, travels with the repository, and can be version-controlled. Developers can review, edit, and refine these memory files just like any other code artifact. The memory becomes part of the project’s documentation infrastructure rather than an opaque external system.
The filesystem also enables memory across different agent types. When a sub-agent discovers important information during its task, it can write findings to project files that persist beyond that sub-agent’s limited lifetime. The main supervisor agent or future sub-agents can then retrieve this information as needed, which is useful for extended coding sessions and large codebases.
3. Parallel Sub-Agent Dispatch
This represents Claude Code’s most significant architectural innovation. The ability to spawn multiple independent sub-agents that execute subtasks concurrently with their own context windows fundamentally changes what’s computationally feasible.
When Claude Code encounters a task like “document the context passed to each template in this project,” it doesn’t try to sequentially read every template file within its own context. Instead, it spawns multiple sub-agents in parallel: one for index templates, one for database templates, one for table templates, and so on. Each sub-agent receives a narrow, focused prompt containing only the information relevant to its specific subtask.
This architecture provides three critical benefits:
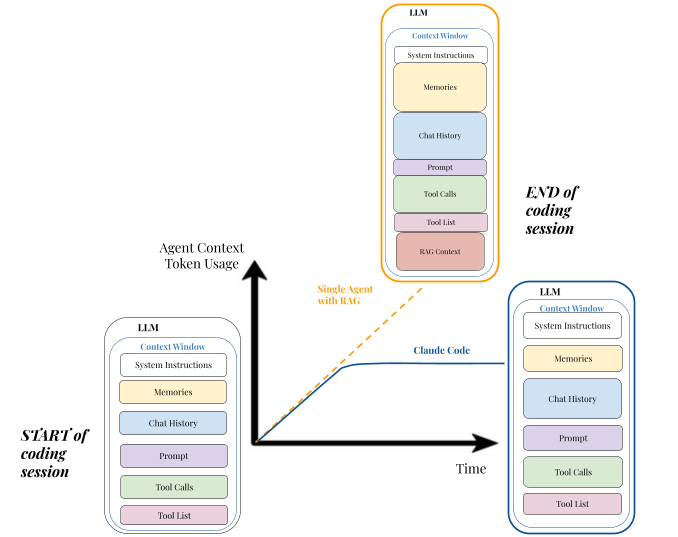
Token efficiency through context isolation. Sub-agents don’t need to carry the full conversation history of the main agent. If the main agent has spent 150,000 tokens discussing various aspects of the project, a sub-agent spawned to search for authentication code doesn’t need any of that history. It receives a focused prompt like “Search this codebase for authentication and authorization logic. Document your findings concisely.” This allows the system to process vastly more information than would fit in any single context window.
Computational speed through parallelization. Attention mechanisms in transformers scale quadratically with sequence length. Processing a 200,000 token context is dramatically slower than processing five 40,000 token contexts. By running sub-agents in parallel, Claude Code can process five search tasks simultaneously, each operating at peak speed with small context windows. This can reduce task completion time by 90% compared to sequential single-agent approaches.
Improved reasoning through focus. A sub-agent attending only to tokens relevant to its narrow task experiences less “noise” from unrelated information. This focused attention leads to more accurate results. As context windows grow beyond 200,000 tokens, models demonstrably become less effective at retrieving and reasoning about information—a phenomenon sometimes called the “lost in the middle” problem. Sub-agents sidestep this by never accumulating massive contexts in the first place.
The sub-agent pattern also enables specialization. Claude Code can dispatch different types of sub-agents optimized for different tasks: a “general-purpose” agent for broad research, specialized agents for code review, and custom agents for project-specific workflows.
4. Comprehensive System Prompts with Rich Examples
While less glamorous than architectural innovations, Claude Code’s detailed system prompts represent months of prompt engineering refinement. These prompts contain extensive guidance on tool usage, including both positive examples (what to do) and negative examples (what to avoid).
Consider the guidance for the Task tool (which spawns sub-agents). The system prompt explicitly states:
“When NOT to use the Agent tool: If you want to read a specific file path, use the Read or Glob tool instead of the Agent tool, to find the match more quickly. If you are searching for code within a specific file or set of 2-3 files, use the Read tool instead of the Agent tool, to find the match more quickly.”
This negative example prevents the agent from over-using sub-agents for trivial tasks where direct tool use would be more efficient. Without such guidance, naive agents spawn sub-agents for simple file reads, wasting tokens and time.
The system prompts also encode sophisticated behavioral patterns like Test-Driven Development. Claude Code is instructed to write failing tests first, implement just enough code to pass those tests, then move to the next feature. This discipline keeps the agent grounded in verifiable progress rather than speculative implementation.
Critical security and safety guidance also lives in system prompts. Bash tool usage includes warnings about validating directory existence before file operations, proper error handling, and avoiding destructive commands without confirmation. These guardrails prevent common failure modes where agents accidentally damage project state.
Why Sub-Agents Matter: A Deeper Look
The effectiveness of Claude Code’s sub-agent architecture deserves deeper examination, as it represents a fundamental shift in how we architect agentic AI systems.
Traditional single-agent systems face an inherent tension: context windows enable them to “see” large amounts of information, but LLMs struggle to effectively utilize that information as context grows (see Needle in Haystack paper). A 200,000 token context window sounds powerful until you realize the model must process quadratically more computations for attention, leading to slower responses and degraded reasoning about information in the middle of that context.
Sub-agents elegantly resolve this tension through a divide-and-conquer strategy. Instead of one agent trying to hold everything in its head, Claude Code maintains a lightweight supervisor that coordinates many focused workers. The supervisor never needs to read the full contents of twenty different files—it just needs to understand the summary reports from sub-agents that did read those files.
This mirrors effective organizational structures in human engineering teams. A tech lead doesn’t personally review every line of code in a large project. They delegate focused reviews to team members, who return with summarized findings and recommendations. The tech lead synthesizes these reports to make architectural decisions without drowning in implementation details. Claude Code’s sub-agent architecture implements this same organizational principle.
The parallel execution aspect cannot be overstated. When Claude Code needs to document template contexts across 47 HTML files, spawning five sub-agents that complete their work in 1-2 minutes each is dramatically different from a single agent sequentially processing 47 files over 10-15 minutes. This isn’t just about developer time—it’s about what becomes computationally feasible. Tasks that would be too expensive or slow with a single agent become practical with parallelization.
Importantly, Claude Code encourages developers to explicitly request sub-agent usage. Simply adding “Use sub-agents” to a request causes Claude Code to more aggressively decompose the task and dispatch parallel workers. This human guidance helps the agent understand when comprehensive breadth-first exploration justifies the token cost.
Claude Code’s Tool Ecosystem
The power of any agentic system depends on its tool ecosystem. Claude Code offers parallel tool execution for read-only tools while write tools are run sequentially for safety. Details on the suspected TypeScript code underlying many these tools can be found here (your mileage may vary). Claude Code provides a sophisticated set of tools that enable comprehensive codebase manipulation:
Core Tools
File manipulation tools (Read, Write, Edit/MultiEdit, NotebookEdit/Read for Jupyter) give the agent full control over the filesystem. The Edit tool deserves special mention—rather than requiring the agent to regenerate entire files, it performs precise string replacements. This dramatically reduces tokens used and eliminates errors from the agent forgetting to include unchanged portions of files. Notebook Edit/Read tools provide Jupyter notebook cell operations with structure preservation. Notice that Claude Code has multiple modular tools instead of one generic file editing tool. Each tool facilitates LLM-friendly guarantees on functionality.
Search and discovery tools (Glob, Grep, LS) provide multiple strategies for finding code. Glob supports pattern-based file discovery (“**/*.ts”), Grep enables content-based search with full regex support, and LS (list directories tool) provides directory exploration. The system prompt carefully guides when to use each tool, preventing inefficient choices like using Grep when Glob would suffice.
Execution tools (Bash) allow the agent to run code, execute tests, and verify its work. The Bash tool includes sophisticated safety guidance (such as sandbox support) about validating paths and handling errors properly. claude-3-5-haiku is used for simpler calls like parsing Bash commands as opposed to calling claude-3-7-sonnet (before Anthropic’s recent October 2025 update to Claude Sonnet 4.5).Claude Code also uses claude-3-5-haiku to evaluate whether the Bash command has any prompt injection security risks. The Bash tool considers whether a read (ls, grep, etc.) vs write (curl, touch, make, npm, etc.) operation needs to be performed to drive sandbox mode decision.
Architectural tools (Architect) let the agent design system architecture before implementation, separating planning from execution. This tool explicitly produces designs without code, preventing premature implementation.
Web tools (WebFetch, WebSearch) enable the agent to consult documentation, search for solutions to errors, and access current information beyond its training data.